
Sphinx - Multi-valued атрибуты и joined поля
В предыдущей статье я показал, как можно использовать Sphinx для индексации базы данных MS SQL Server, а также рассказал про дельта-индексы.
В этой статье я продолжу рассматривать эту тему и расскажу про multi-valued атрибуты и joined поля, которые могут быть полезны, когда каждая строка в индексируемой таблице через внешний ключ связана с одной или несколькими строками в другой таблице, по которым также необходимо выполнять фильтрацию, группировку или полнотекстовый поиск.
Подготовка базы данных
В этой статье мы снова будем использовать базу данных AdventureWorks, которую можно скачать с сайта codeplex.com. На этот раз для индексации нам потребуется информация о заказах, клиентах, и товарах.
Пример запроса для получения информации о заказах и клиентах:


Пример запроса для получения информации о товарах в заказах:


Подготовка файла конфигурации
Для начала создадим индекс order, содержащий информацию о заказах. Позже мы добавим в него multi-valued атрибут и joined поле.
Во-первых, добавим в файл конфигурации блоки searchd и source base:

Во-вторых, добавим в файл конфигурации блоки source order_base и source order:

И в-третьих, добавим в файл конфигурации блок index order:

Выполним индексацию при помощи команды:
c:\sphinx\bin\indexer order --config c:\sphinx\data\config.txt --rotate --print-queries
И, наконец, попробуем сделать какой-нибудь запрос, например:
select * from `order`;

Теперь у нас есть готовый индекс, на котором мы можем рассмотреть работу multi-valued атрибутов и joined-полей.
Multi-valued атрибуты
Обычные атрибуты могут содержать в себе только одно значение. Это может быть текст или число, но в любом случае значение будет только одно. Тем не менее в некоторых случаях бывает удобно хранить в одном атрибуте сразу несколько значений, чтобы выполнять по ним фильтрацию или группировку. Эту задачу как раз и выполняют multi-valued атрибуты.
Определение multi-valued атрибута в файле конфигурации выглядит следующим образом:
sql_attr_multi = ATTR-TYPE ATTR-NAME from SOURCE-TYPE [; QUERY] [; RANGE-QUERY]
Multi-valued атрибуты могут хранить только целочисленные значения. ATTR-TYPE задаёт тип атрибута и может иметь значение uint, bigint или timestamp.
ATTR-NAME задаёт название атрибута.
SOURCE-TYPE задаёт то, каким образом значения этого атрибута будут получены из источника данных, и может иметь значение field, query или ranged-query.
Если при объявлении атрибута используется значение field, то источник данных в основном запросе (опция sql_query в блоке source) должен вернуть для этого атрибута соответствующую колонку, в которой в виде строк будут содержаться значения - целые числа, разделённые запятыми. Такой способ индексации обычно применяться, если объединение нескольких целочисленных значений в одну строку на уровне базы данных не очень затратно.
Если при объявлении атрибута используются значения query или ranged-query, то источник данных в основном запросе не должен возвращать колонку для этого атрибута. Вместо этого Sphinx сделает один (при использовании query) или несколько (при использовании ranged-query) дополнительных запросов, используя QUERY и RANGE-QUERY (которые по назначению напоминают опции sql_query и sql_query_range в блоке source). Эти запросы должны вернуть результат, содержащий две колонки: id документа и значение атрибута. Sphinx самостоятельно сгруппирует полученные значения атрибутов по id документа.
Добавление multi-valued атрибута
Добавим в индекс order multi-valued атрибут product_id, содержащий id товаров в каждом заказе. Для этого в блок source order добавим следующее определение:

Обновим индекс и попробуем сделать следующий запрос:
select * from `order`
where match('@customer_name Jack');

Теперь по каждому заказу мы знаем список товаров этого заказа и можем использовать эту информацию для фильтрации и группировок.
Фильтрация по multi-valued атрибуту
Фильтрация по multi-valued атрибуту в выражении where выполняется точно также, как и фильтрация по обычному целочисленному атрибуту. Единственным нюансом в этом случае является то, что указанному условию должно соответствовать хотя бы одно из значений, содержащихся в атрибуте.
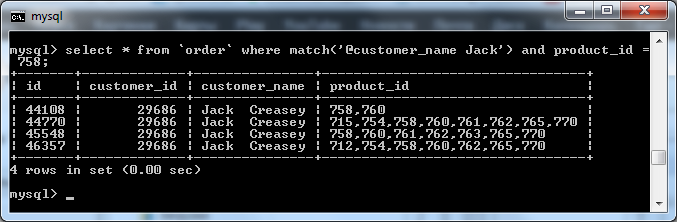
Так, например, мы можем найти заказы, содержащие товар с определённым id:
select * from `order`
where match('@customer_name Jack') and product_id = 758;
Точно также можно найти товары, содержащие одновременно несколько товаров с определёнными id:
select * from `order`
where match('@customer_name Jack') and product_id = 754 and product_id = 758;

Такой запрос на первый взгляд может показаться странным, поскольку обычные целочисленные атрибуты не могут быть одновременно равны двум различным значениям, но для multi-valued атрибутов это нормально.
Если же мы хотим найти заказы, содержащие хотя бы один из товаров с определённым id, то можем воспользоваться оператором in.
select * from `order`
where match('@customer_name Jack') and product_id in (754, 770);

Группировка по multi-valued атрибуту
Более интересной особенностью multi-valued атрибутов является группировка. Попробуем выполнить группировку по атрибуту product_id:
select * from `order`
where match('@customer_name Jack') and product_id = 758 group by product_id;

На первый взгляд, мы получили немного странные результаты, поскольку некоторые строки просто дублируются несколько раз, но на самом деле всё достаточно просто. При группировке по multi-valued атрибуту Sphinx создаёт одну группу на каждое уникальное значение этого атрибута во всех найденных документах. При этом к каждой группе добавляются атрибуты её первого документа.
Таким образом, при группировке по атрибуту product_id, мы получаем уже не заказы, а товары этих заказов. При этом в каждом товаре оказываются сгруппированы те заказы, которые содержат этот товар.
Воспользуемся функцией groupby, чтобы получить id товара, по которому сгруппированы заказы и функцией group_concat, чтобы получить список id этих заказов:
select groupby(), group_concat(id) from `order`
where match('@customer_name Jack') and product_id = 758 group by product_id;

Joined поля
Joined поля, также как и обычные поля, позволяют выполнять полнотекстовый поиск документов по значению поля. В этом они практически ни чем не отличаются от обычных полей. Основное отличие заключается в том, что при индексации данные из источника получаются не в основном запросе, а в одном или нескольких дополнительных запросах (аналогично multi-valued атрибутам). При этом для каждого документа в дополнительном запросе может быть получено несколько значений, которые объединяются в одно поле.
Определение joined поля в файле конфигурации выглядит следующим образом:
sql_joined_field = FIELD-NAME from SOURCE-TYPE ; QUERY [; RANGE-QUERY]
FIELD-NAME задаёт название поля.
SOURCE-TYPE задаёт то, каким образом значения этого поля будут получены из источника данных, и может иметь значение query, ranged-query или payload-query.
Использование значений query или ranged-query полностью аналогично использованию этих же значений в multi-valued атрибутах, т.е. источник данных в дополнительных запросах должен возвращать две колонки: id документа и значение поля. Единственным отличием от multi-valued атрибутов является то, что id документов должны быть обязательно упорядочены по возрастанию.
Использование значения payload-query позволяет для каждой пары id документа и значения поля также указать в виде целого числа её полезность (payload), которая будет учитываться в сортировке результатов. Это число должно возвращаться третьей колонкой в дополнительных запросах.
Добавление joined поля
Используя payload-query, добавим в индекс order joined поле product_name, содержащее названия товаров в каждом заказе. В качестве показателя полезности будем использовать количество каждого товара в заказе. Для этого в блок source order добавим следующее определение:

Обновим индекс и попробуем поискать заказы по названию товаров:
select * from `order`
where match('@customer_name Alex @product_name Sport');

Показатель полезности (payload)
Рассмотрим отдельно первые два заказа. С помощью запроса к базе данных узнаем количество каждого из товаров в этих заказах:


Как мы видим, в каждом заказе есть только один товар со словом «Sport», причём в количестве одной штуки. Поскольку это количество является показателем полезности, оба заказа имеют одинаковый вес при сортировке результатов.
Попробуем увеличить вес второго заказа, увеличив в нём количество товаров:

Теперь обновим индекс и повторим предыдущий запрос:
select * from `order`
where match('@customer_name Alex @product_name Sport');

Как мы видим, заказ, который раньше был на втором месте теперь поднялся на первое.
Заключение
В этой статье я рассказал про использование multi-valued атрибутов и joined полей, закончив тем самым рассказывать про индексацию баз данных.
В следующей статье я постараюсь немного рассказать про использование в качестве источника данных xml-файлов.
Скачать материалы к этой статье (скрипты и файлы конфигурации)
Игорь, добрый день!
ОтветитьУдалитьУ меня возник вопрос по постройке индекса по нескольким таблицам.
Вроде делаю все по науке, но не получается.
----------------------------------
В конфиге:
# Поля, по которым строится индекс
source order_base : base
{
# tOrder - таблица заказов
sql_field_string = name # sName
sql_field_string = namesearch # sNameSearch
# tLot - таблица лотов, связана через id с таблицей tOrder
sql_field_string = subjectsearch # sSubjectSearch
sql_field_string = infoproductsearch # sInfoProductSearch
# tDocContent - таблица с контентом файлов, которые связаны с tOrder
sql_field_string = doccontent # sContent
}
# И такой запрос
sql_query = \
select \
ord.idOrder AS 'id', \
ord.sName AS 'name', \
ord.sNameSearch AS 'sNameSearch', \
lot.sSubjectSearch AS 'subjectsearch', \
lot.sInfoProductSearch AS 'infoproductsearch' , \
doc.sContent AS 'doccontent', \
from PoiskTorgov.dbo.tOrder ord \
left join PoiskTorgov.dbo.tLot lot \
on lot.idOrder = ord.idOrder \
left join PoiskTorgov.dbo.tDocContent doc \
on doc.idOrder = ord.idOrder \
where ord.idOrder between $start and $end
--------------------
Ищу выражение "пираты карибского моря", это выражение находится только в таблице tDocContent, но ниче не находит.
Индекс вроде строится (хотя во время постройки появляются warning'и, но они игнорируются).
Что делаю неправильно, где копать?
С варнингами понятно, не существующие поля вводил. но индекс не работает.
ОтветитьУдалитьЗапрос select * from order возвращает ошибку типа - You have an error ... near 'order' - понятное дело, что ошибка в sql'e, но в чем заключается не пойму (
БД - MS SQL SERVER 2008 R2
Кодировка в БД юникод (либо cp1251), а индексе utf-8
Все это прекрасно работало с одной таблицей, в этой статье http://chakrygin.ru/2013/04/sphinx-db-indexing-and-delta-indexes.html, я с вашей помощью (то самое егромное дерево комментариев:) ) справился с задачей и поиск летал у меня. Тут я поменял тока запрос и добавил поля в других таблицах, по которым будут происходить индексация и соответственно поиск. Также планируется добавить другие поля, по которым будет идти сортировка
Хм, мне на почту пришёл коммент, но его тут нет. Пропал?
ОтветитьУдалить>> Запрос select * from order возвращает ошибку
Так вроде уже разбирались с этим. кавычек нет: select * from `order`
И нужно чтобы везде были одинкаовые кодировки (см. последнюю статью)
В бд поля nvarchar (или cast к ним при индексации), индекс utf-8, при подключении указать кодировку utf-8. Опция mssql_unicode = 1.
Кавычки (двойные, одинарные и апострофы) ставлю та жа ошибка, тока с дополнительными кавычками.
ОтветитьУдалить>> mssql_unicode = 1
- уже включена.
Я ж говорю, в конфиге поменял только запрос и включил дополнительные поля (вот тут: source order_base : base { ...
)
Смари, задачу лучше в 2-х словах опишу, может у тя идея получше будет:
Есть 3 таблицы (tOrder, tLot, tDocContent), последние 2 связаны с первой через id.
В каждой таблице по два поля, по которым должен строиться индекс. Но такой момент, если фразу нашли в полях 2-х последних таблиц, на выдаче должна появиться строка из таблицы tOrder (для этого в тех таблицах и присутствует id на соответствующий id таблицы tOrder).
Может я запрос неправильно делаю? Нужны ли тут multi-valued атрибуты, если да, то как их прикрутить в моем случае?
Судя по всему, тебе joined-поля нужны.
ОтветитьУдалитьВ статье пример 1-в-1, только там заказы ищутся по названию одного или нескольких товаров в заказе.
А ошибки в запросе - ну тут только могу посоветовать удалить всё нафиг и попробовать пошагово добавлять новые поля, пока не найдёшь ошибку. И вообще проверь, что у тебя запрос сам по себе работает.
Все вернул как было, запрос в командной строке - select * from 'order'; - возвращает ту же ошибку, а на сайте поиск срабатывает нормально.
ОтветитьУдалитьТакой запрос к MS SQL срабатывает нормально:
select top 50
ord.idOrder AS 'id',
ord.sName AS 'name',
ord.sNameSearch AS 'namesearch',
lot.sSubjectSearch AS 'subjectsearch',
lot.sInfoProductSearch AS 'infoproductsearch',
lot.idOrder AS 'idlotorder',
doc.sContent AS 'doccontent',
doc.idOrder AS 'iddocorder'
from PoiskTorgov.dbo.tOrder AS ord
left join PoiskTorgov.dbo.tLot AS lot
on lot.idOrder = ord.idOrder
left join PoiskTorgov.dbo.tDocContent AS doc
on doc.idOrder = ord.idOrder
но если я добавлю условие - WHERE doc.sContent = 'пираты' - , то возвращает ошибку:
Warning: mssql_query() [function.mssql-query]: message: Типы данных text и varchar в операторе equal to несовместимы. (severity 16)
блин, что за ошибка, причем тут типы данных и оператор equal, его я не использую и вижу первый раз.
п.с. Слово "пираты" в таблице есть
>> Судя по всему, тебе joined-поля нужны.
- Если я буду использовать эти поля, стоит ли основной запрос в конфиге делать таким каким я его делаю?
я так и хочу искать - вводит чел фразу, ищу в поле name таблицы tOrder, если там ничего нет, то в двух других таблицах, связанных с первым по id.
ОтветитьУдалитьА вопрос был в другом, если я использую join-поля, надо ли запрос делать таким как в предыдущем комментарии или в запросе получить только поля из таблицы tOrder?
Если связь один ко многим, то должно быть три отдельных запроса. 1 основной с заказами и два на каждый joined-field по связанной таблице.
ОтветитьУдалитьДобрый день.
ОтветитьУдалитьЧета не срабатывает инструкция. Я добавляю в конфиг код для joined-поля, но индекс вообще не строится, хотя появляется командная строка и видно, что что-то строится, ну как обычно, только файлы в папке index/ не появляются.
Я прикрепляю картинку с участком кода, тут код не читабельный. посмотри пожалста что не так, может последовательность не правильная или еще че-нибудь
Запрос неправильный. Ты для joined-поля делаешь селект из Order join DocContent, а нужно просто из DocContent, чтобы первая колонка была - id заказа, а вторая индексируемый текст. Причём может быть много строк с одинаковым id заказа. Sphinx сам их сджойнид.
ОтветитьУдалитьблин, может я чета не понимаю, но не срабатывает, вот переделанный запрос:
ОтветитьУдалитьsql_joined_field = doccontent from payload-query; \
select doc.idOrder, doc.sContent \
from Poisk.dbo.tDocContent as ord
т.е., тут беру тока 2 поля из таблицы tDocContent и все равно не появляются файлы в index/
Вот как переделать этот запрос?
Кстати поля doccontent из первой строки в таблице tDocContent нет, может эта ошибка? просто я аналогично со статьей делал, там тоже какое-то левое название product_name. да и ктому же у тя в статье двойной запрос с inner join'ом. В голове все смешалось
payload-query требует три колонки. используй просто query.
ОтветитьУдалить>> Кстати поля doccontent из первой строки в таблице tDocContent нет
doccontent - это название поля, которое ты создаёшь, по нему ты потом сможешь отдельно делать поиск match('@doccontent твой поисковой запрос')
У меня join-ы, потому что мне нужно было данные для индексации из нескольких таблиц вытащить. У тебя таблица однаtDocContent. Зачем тебе join-ы?
>> У меня join-ы, потому что мне нужно было данные для индексации из нескольких таблиц вытащить.У тебя таблица одна tDocContent. Зачем тебе join-ы?
ОтветитьУдалить- Как? я же задачу описал, ----------------
всего у меня три таблицы, одна главная (tOrder - таблица заказов), а другие 2 (tLot - лоты, tDocContent - контенты связанных с заказом документов) связаны с ним по id. Получается с одним заказом могут быть связаны от нуля до несколько лотов и / или документов. В каждой таблице минимум одно поле для индексации. Индекс должен быть построен так, что если слово будет найдено в tDocContent и / или в tLot, на выдаче появлялись данные из tOrder.
Вот такая задача.
-----------------
Так join'ы ты и сам посоветовал мне )
Одним словом, задача такая как я описал, и у меня никак не получается построить индекс. Помоги пожалуйста.
Запрос для joined-поля должен получать информацию ТОЛЬКО для этого поля. это id заказа и индексируемый текст. Это всё у тебя в таблице tDocContent. И ещё раз, зачем тебе там join-ы? (вопрос риторический)
ОтветитьУдалитьУ меня в таблице с позициями заказов не было индексируемого текста. Там были только id заказа и id товара. А мне нужно было название товара, поэтому я получал его через join. Поэтому мне нужен был join.
Если ты не понимаешь как это работает, то возьми и последовательно выполни пример из статьи, там есть ссылка на готовые конфиги, которые точно работают. Возьми запросы оттуда, посмотри что они возвращают, попробуй сам что-нибудь добавить в готовые примеры. Иначе ты никогда не разберёшься, как это работает.
>> Это всё у тебя в таблице tDocContent. И ещё раз, зачем тебе там join-ы? (вопрос риторический)
ОтветитьУдалить- Не знаю, мне нужно было, чтобы в индексе была какая-то связь между таблицей заказов (tOrder) и таблицей документов (tDocContent). Если я в индекс засуну 2 параллельных запроса - один для заказов, другой для документов, то как мне объяснить индексу, что они должны быть связаны (связь один ко многим)?
Поэтому я думал либо 1 запрос с join'ами сделать, либо через joined-поля, ни то, ни другое не работает. То что в tDocContent уже есть поле idOrder (указывающий на соответствующий id заказа), я думаю ничего не меняет, т.к., в индекс я его (поле idOrder из tDocContent) не добавляю.
>> Если ты не понимаешь как это работает,...
- Видимо не понимаю, вроде смотришь, задача практически у нас совпадает, скопируй и вставь что называется, но нет, не срабатывает :)
>> Если я в индекс засуну 2 параллельных запроса - один для заказов, другой для документов, то как мне объяснить индексу, что они должны быть связаны (связь один ко многим)?
ОтветитьУдалитьВ основном запросе у тебя id - это ID закза. В запросе для joined поля 1 колонка - это id заказа. Сфинкс на основании этого их связывает.
>> В запросе для joined поля 1 колонка - это id заказа.
ОтветитьУдалить- Игорь, ты сбиваешь меня с толку ))
все таки, мне использовать joined-поля или нет? Вот задача на пару постов выше, как бы поступил / решил?
Я поколдую над задачей, но я хочу точно знать правильное направление
В запросе для joined поля ПЕРВАЯ колонка - это id заказа.
ОтветитьУдалитьДа, используй joined-поля
Правильное направление - это ПРОЧИТАТЬ, как это работает, прежде чем методом тыка пытаться настроить индекс.
Такой вопрос, в статьях я не нашел. Как добавить в индекс неиндексируемые поля?
ОтветитьУдалитьНапример, есть поле sName в индекс добавляется под именем name, но в поиске он участвовать не будет, тока на выдаче. Или, к примеру, поле с датой, которая будет нужна для сортировки или для какого-либо условия. Как такие поля нужно добавлять? так же как индексируемые, вот так:
source order_base : base
{
sql_field_string = namesearch
}
?
>> Как добавить в индекс неиндексируемые поля?
ОтветитьУдалитьПоля - это и есть индекс. Читай статью про поля и атрибуты.
Получилось кое-как))
ОтветитьУдалитьЯ не стал делать отдельно запрос для joined-полей, а просто сделал один запрос с обычным left join. Теперь когда ищу че-нить в связанной таблице, мне поисковик мигом возвращает соответствующее название заказа.
Тока такой момент, мне приходится искать только по одному индексированному полю, а мне надо чтобы по всем.
Вот мой запрос
$qSph = "SELECT * FROM `order` WHERE MATCH('@doccontent ".garble($searchPh)."')"; - так, все ок
но из таблицы заказов я проиндексировал поле, там тоже надо искать. Добавляю в запрос, в MATCH, такое -
@namesearch ".garble($searchPh)." - возвращается ошибка
Вопрос: Как искать по всем индексированным полям (точнее по всем индексам)?
Нужно открыть документацию и почитать про синтаксис оператора match
ОтветитьУдалитьhttp://sphinxsearch.com/docs/2.1.1/boolean-syntax.html
http://sphinxsearch.com/docs/2.1.1/extended-syntax.html
Добрый день!
ОтветитьУдалитьВсе сделал, все работает, спасибо за помощь.
Объясни пожалуйста такой момент (или дай ссылку где почитать), решил отказаться от API (не знаю, API возвращает 3 значения вместо 4), вывожу просто список результата поиска:
echo $lSphinx['weight'].' = '.$lSphinx['id'] .' - '. $lSphinx['name'] .'
';
но почему-то вес (weight) выдает такие значения - 3572, 3552, 3552, 3552. (в результате 4 значения)
Вопрос - почему такие значения?
При использовании API максимум выдавалось - 9, по-мойму.
Не знаю, возможно при поиске через API используется другой ранкер или другая формала ранжирования.
ОтветитьУдалитьИгорь, здравствуйте. Помогите разобраться в MVA. Пытаюсь добавить mav (sql_attr_multi = unit ages_id from query;select id, ages_id from catalog). При индексации вылетает ошибка:
ОтветитьУдалитьERROR: source 'testsrc1': expected attr type ('uint' or 'timestamp' or 'bigint')
in sql_attr_multi, got 'unit tag from query; select id, ages_id AS tag
from catalog'.
Что я не так делаю?
Вот мой source:
sql_query_pre = REPLACE INTO sph_counter SELECT 1, MAX(adplace_id) FROM tbl_adplaces
sql_query_pre =\
CREATE OR REPLACE \
VIEW `catalog` AS \
SELECT p.`adplace_id`,p.adplace_id AS id, p.`address`, p.`name` ,p.`internal_comment` , p.`description`,0 as deleted, p.`position`,X(p.position) AS latitude ,Y(p.position) AS longitude,\
own.`description` AS owner_description, own.`name` AS owner_name, own.`site` AS owner_site,\
own.`address` AS owner_address, own.`internal_comment` AS owner_internal_comment,\
top.`name` AS top_name, top.type_of_place_id AS top_id,\
pt.`name` AS pt_name, pt.place_type_id AS pt_id,\
audience.`audience_id` AS aud_id,\
ages.`age_id` AS ages_id ,\
gender.gender_id AS gend_id,\
p.contacts AS contacts,\
p.price AS price,\
city.city_id AS city_id\
FROM `tbl_adplaces` p \
JOIN `tbl_owners` own ON p.owner_id = own.owner_id \
JOIN `tbl_type_of_place` top ON p.type_of_place_id = top.type_of_place_id\
JOIN `tbl_place_type` pt ON p.place_type_id = pt.place_type_id\
JOIN `tbl_audiences` audience ON p.adplace_id = audience.adplace_id\
JOIN `tbl_audience_ages` ages ON audience.audience_id = ages.audience_id\
JOIN `tbl_audience_genders` gender ON audience.audience_id = gender.audience_id\
JOIN `tbl_cities` city ON p.city_id = city.city_id\
WHERE p.adplace_id <= ( SELECT max_doc_id FROM sph_counter WHERE counter_id=1 )
sql_query_range = SELECT MIN(adplace_id),MAX(adplace_id) FROM catalog
sql_range_step = 1000
sql_query = \
SELECT * \
FROM catalog \
WHERE adplace_id>=$start AND adplace_id<=$end
sql_attr_uint = id
sql_attr_uint = deleted
sql_attr_uint = top_id
sql_attr_uint = pt_id
sql_attr_uint = gend_id
sql_attr_uint = contacts
sql_attr_uint = price
sql_attr_uint = city_id
sql_attr_float = latitude
sql_attr_float = longitude
sql_attr_multi = unit ages_id from query;\
select id, ages_id\
from catalog
sql_query_info = SELECT * FROM catalog WHERE adplace_id=$id
Может опечатка, uint, а не unit
ОтветитьУдалитьДа, спасибо, была опечатка.
ОтветитьУдалитьСейчас выдает ошибку:
"ERROR: index 'test1': multi-valued attribute 'ages_id' of wrong source-type found in query; must be 'field'." В чем сейчас моя ошибка?
Если я так объявляю:sql_attr_multi = uint ages_id from field, то индексация проходит, но все так же с дубликацией документов. А мне нужно добиться того, что бы дубликации не было.
ОтветитьУдалитьНе понял про дубликацию.
ОтветитьУдалитьВозможно проблема в том, что поле ages_id есть и в основном запросе и в запросе на mva атрибут. Если в mva тип field, то он берёт значения из основного запроса. Если используется query, то в основном запросе этого поля быть не должно